분산 추론#
일부 언어 모델, DeepSeek V3, DeepSeek R1 등을 포함하여, 크기가 너무 커서 단일 머신의 GPU에 적합하지 않습니다. Xinference는 여러 머신에서 이러한 모델을 실행하는 것을 지원합니다.
Added in version v1.3.0.
지원되는 엔진#
지금, Xinference는 여러 워커에서 모델을 실행할 수 있는 다음과 같은 엔진을 지원합니다.
SGLang (v1.3.0에서 지원)
vLLM (v1.4.1에서 지원)
MLX (v1.7.1부터 지원)은 현재 분산 모드에서 모든 모델을 지원하지 않습니다. 현재 다음과 같은 모델 유형을 지원합니다. 다른 필요 사항이 있으시면 xorbitsai/inference#issues 에 GitHub issue를 제출하여 지원을 요청해 주시기 바랍니다.
DeepSeek v3와 R1
Qwen2.5-instruct 및 동일한 모델 아키텍처를 가진 다른 모델들.
Qwen3 및 동일한 모델 아키텍처를 가진 다른 모델들.
Qwen3-moe 및 동일한 모델 아키텍처를 가진 다른 모델들.
사용#
먼저, 분산 추론을 지원하려면 최소 2개의 작업 노드가 필요합니다. :ref:`클러스터에서 Xinference 실행하기 <distributed_getting_started>`를 참조하여 supervisor 노드와 worker 노드로 구성된 Xinference 클러스터를 생성하십시오.
vLLM(v0.11.0+) 주의사항: vLLM v0.11.0 버전부터, vLLM을 사용한 분산 배포에는 Xinference >= v1.17.1 버전이 필요합니다. 기존의 --n-worker 매개변수 설정 외에도, 모델을 시작할 때 반드시 tensor_parallel_size (이를 **GPU 개수**로 설정) 및 pipeline_parallel_size=1 매개변수를 함께 설정해야 합니다.
그런 다음, Web UI를 사용하는 경우 선택적 구성에서 원하는 머신 수를 ``worker count``로 선택하세요. 명령줄을 사용하는 경우 모델을 시작할 때 ``–n-worker <머신 수>``를 추가하세요. 모델은 그에 따라 여러 작업 노드에서 시작됩니다.
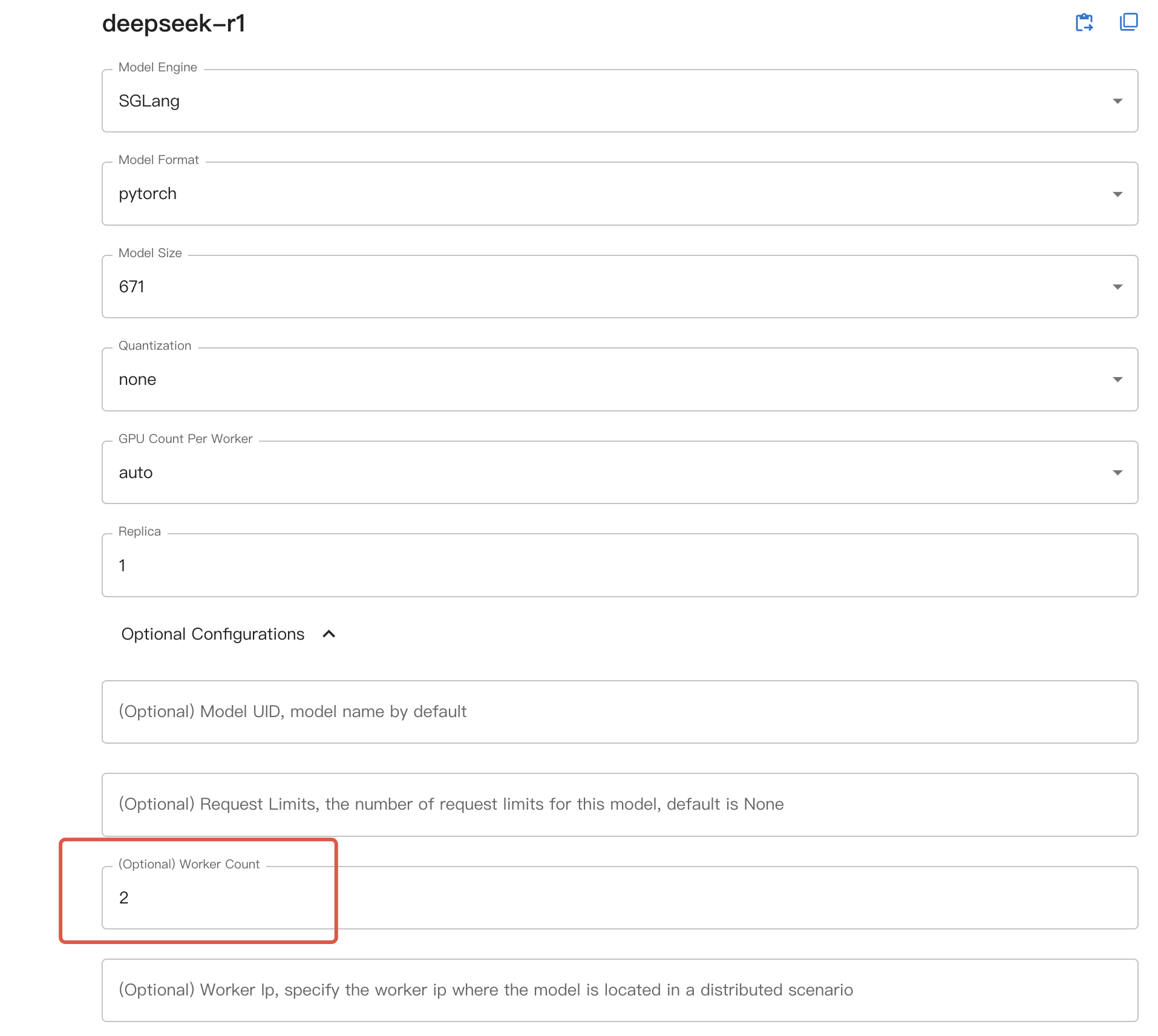
분산 추론을 사용할 때, Web UI의 GPU count 또는 명령줄의 ``–n-gpu``는 이제 각 작업 노드의 GPU 수를 나타냅니다.