이미지#
Xinference를 사용하여 이미지를 생성하는 방법을 학습합니다.
소개#
Images API는 이미지와 상호작용하는 두 가지 방법을 제공합니다:
텍스트-이미지 엔드포인트는 텍스트로부터 처음부터 이미지를 생성합니다.
그림 생성 엔드포인트는 주어진 이미지의 변형을 생성할 수 있게 합니다.
API 엔드포인트 |
OpenAI 호환 엔드포인트 |
|---|---|
Text-to-Image API |
/v1/images/generations |
Image-to-image API |
/v1/images/variations |
지원되는 모델 목록#
Xinference에서 Text-to-image API는 다음 모델을 지원합니다:
sd-turbo
sdxl-turbo
stable-diffusion-v1.5
stable-diffusion-xl-base-1.0
sd3-medium
sd3.5-medium
sd3.5-large
sd3.5-large-turbo
FLUX.1-schnell
FLUX.1-dev
Kolors
hunyuandit-v1.2
hunyuandit-v1.2-distilled
cogview4
Qwen-Image
지원되는 모델 목록
Flux.1-Kontext-dev
Qwen-Image-Edit
빠른 시작#
Text-to-image#
cURL, OpenAI Client 또는 Xinference를 통해 Text-to-image API를 사용해 볼 수 있습니다.
curl -X 'POST' \
'http://<XINFERENCE_HOST>:<XINFERENCE_PORT>/v1/images/generations' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "<MODEL_UID>",
"prompt": "an apple",
}'
import openai
client = openai.Client(
api_key="cannot be empty",
base_url="http://<XINFERENCE_HOST>:<XINFERENCE_PORT>/v1"
)
client.images.generate(
model=<MODEL_UID>,
prompt="an apple"
)
from xinference.client import Client
client = Client("http://<XINFERENCE_HOST>:<XINFERENCE_PORT>")
model = client.get_model("<MODEL_UID>")
input_text = "an apple"
model.text_to_image(input_text)
{
"created": 1697536913,
"data": [
{
"url": "/home/admin/.xinference/image/605d2f545ac74142b8031455af31ee33.jpg",
"b64_json": null
}
]
}
그림에서 그림으로#
이미지에서 이미지로 변환하는 API는 OpenAI의 `이미지 변형 생성 API <https://platform.openai.com/docs/api-reference/images/createVariation>`_를 모방했습니다. cURL, OpenAI 클라이언트 또는 Xinference의 Python 클라이언트를 통해 이미지에서 이미지로 변환하는 API를 사용해볼 수 있습니다.
curl -X 'POST' \
'http://<XINFERENCE_HOST>:<XINFERENCE_PORT>/v1/images/variations' \
-F model=<MODEL_UID> \
-F image=@xxx.jpg \
-F prompt="an apple"
import openai
client = openai.Client(
api_key="cannot be empty",
base_url="http://<XINFERENCE_HOST>:<XINFERENCE_PORT>/v1"
)
client.images.create_variation(
model=<MODEL_UID>,
image=open("image_edit_original.png", "rb"),
prompt="an apple"
)
from xinference.client import Client
client = Client("http://<XINFERENCE_HOST>:<XINFERENCE_PORT>")
model = client.get_model("<MODEL_UID>")
input_text = "an apple"
with open("xxx.jpg", "rb") as f:
model.image_to_image(f.read(), input_text)
{
"created": 1697536913,
"data": [
{
"url": "/home/admin/.xinference/image/605d2f545ac74142b8031455af31ee33.jpg",
"b64_json": null
}
]
}
대형 이미지 모델(예: SD3-Medium, FLUX.1)의 메모리 최적화#
참고
v0.16.1부터 Xinference는 기본적으로 Flux.1 및 SD3.5 시리즈와 같은 대형 이미지 모델에 대해 양자화를 활성화합니다. v0.16.1보다 새로운 Xinference 버전을 사용하는 경우, 작은 GPU 메모리를 가진 머신에서 이러한 대형 이미지 모델을 실행하기 위해 별도로 해야 할 일은 없습니다.
유용한 전달 인수에는 로드 모델에 대한 추가 매개변수가 포함됩니다:
--cpu_offload True: ``True``를 지정하면 추론 과정에서 모델의 구성 요소를 CPU로 오프로드하여 메모리를 절약하며, 이로 인해 추론 지연 시간이 약간 증가할 수 있습니다. 모델 오프로드는 실행이 필요할 때만 모델 구성 요소를 GPU로 이동시키고, 나머지 구성 요소는 CPU에 유지합니다.--quantize_text_encoder <text encoder layer>:우리는bitsandbytes라이브러리를 사용하여 T5-XXL 텍스트 인코더를 로드하고 8비트 정밀도로 양자화합니다. 이를 통해 성능에 미미한 영향만을 주면서도 전체 텍스트 인코더를 계속 사용할 수 있습니다.--text_encoder_3 None: sd3-medium의 경우, 추론 과정에서 메모리 집약적인 47억 매개변수 T5-XXL 텍스트 인코더를 제거하면 메모리 요구량이 크게 줄어들며, 성능 저하는 미미합니다.--transformer_nf4 True: nf4 양자화를 사용하여 transformer를 변환합니다.--quantize: macOS의 MLX 엔진에만 적용됩니다. Flux.1-dev와 Flux.1-schnell은 Mac에서 MLX 엔진을 사용하여 계산하며, `quantize`는 모델을 양자화하는 데 사용할 수 있습니다.
WebUI의 경우, 추가 매개변수를 추가하기만 하면 됩니다. 예를 들어, CPU 오프로드를 활성화하려면 키 ``cpu_offload``와 값 ``True``를 추가하세요.
다음은 v0.16.1부터 기본적으로 사용되는 매개변수를 나열한 것입니다.
모델 |
quantize_text_encoder |
quantize |
transformer_nf4 |
|---|---|---|---|
FLUX.1-dev |
text_encoder_2 |
True |
False |
FLUX.1-schnell |
text_encoder_2 |
True |
False |
sd3-medium |
text_encoder_3 |
N/A |
False |
sd3.5-medium |
text_encoder_3 |
N/A |
False |
sd3.5-large |
text_encoder_3 |
N/A |
True |
sd3.5-large-turbo |
text_encoder_3 |
N/A |
True |
Qwen-Image |
text_encoder |
N/A |
False |
Qwen-Image-Edit |
text_encoder |
N/A |
False |
참고
특정 양자화를 비활성화하려면 해당 옵션을 False로 설정하기만 하면 됩니다. 예를 들어, Web UI의 경우 key ``quantize_text_encoder``에 값 ``False``를 설정하거나, 명령줄의 경우 ``–quantize_text_encoder False``를 지정하여 text encoder의 양자화를 비활성화할 수 있습니다.
CogView4 <models_builtin_cogview4>`에 대해, 양자화가 모델에 미치는 영향이 크다는 것을 발견했습니다. 따라서 VRAM이 제한된 경우, Web UI에서 CPU offload 옵션을 활성화하고, 명령줄에서 모델을 로드할 때 `–cpu_offload True``를 지정하는 것을 권장합니다.
GGUF 파일 형식#
GGUF 파일 형식은 transformer 모듈에 다양한 양자화 옵션을 제공합니다. GGUF 파일을 사용하려면 웹 인터페이스에서 추가 옵션 gguf_quantization 을 지정하거나, 명령줄에서 --gguf_quantization 을 지정하여 Xinference가 기본적으로 GGUF 양자화를 지원하는 모델에 대해 활성화할 수 있습니다. 다음은 기본적으로 지원되는 모델입니다.
모델 |
GGUF 양자화 포맷 지원 |
|
|---|---|---|
FLUX.1-dev |
F16, Q2_K, Q3_K_S, Q4_0, Q4_1, Q4_K_S, Q5_0, Q5_1, Q5_K_S, Q6_K, Q8_0 |
|
FLUX.1-schnell |
F16, Q2_K, Q3_K_S, Q4_0, Q4_1, Q4_K_S, Q5_0, Q5_1, Q5_K_S, Q6_K, Q8_0 |
|
sd3.5-medium |
F16, Q3_K_M, Q3_K_S, Q4_0, Q4_1, Q4_K_M, Q4_K_S, Q5_0, Q5_1, Q5_K_M, Q5_K_S, Q6_K, Q8_0 |
|
sd3.5-large |
F16, Q4_0, Q4_1, Q5_0, Q5_1, Q8_0 |
|
sd3.5-large-turbo |
F16, Q4_0, Q4_1, Q5_0, Q5_1, Q8_0 |
|
Qwen-Image |
F16, Q3_K_M, Q3_K_S, Q4_0, Q4_1, Q4_K_M, Q4_K_S, Q5_0, Q5_1, Q5_K_M, Q5_K_S, Q6_K, Q8_0 |
|
Qwen-Image-Edit |
Q2_K, Q3_K_M, Q3_K_S, Q4_0, Q4_1, Q4_K_M, Q4_K_S, Q5_0, Q5_1, Q5_K_M, Q5_K_S, Q6_K, Q8_0 |
|
Qwen-Image-Edit-2509 |
Q2_K, Q3_K_M, Q3_K_S, Q4_0, Q4_1, Q4_K_M, Q4_K_S, Q5_0, Q5_1, Q5_K_M, Q5_K_S, Q6_K, Q8_0 |
|
예:
xinference launch --model-name FLUX.1-dev --model-type image --gguf_quantization Q2_K --cpu_offload True
Q2_K 양자화를 사용하면 Flux.1-dev를 실행하는 데 약 5GB의 VRAM만 필요합니다.
비내장 지원 GGUF 양자화 모델의 경우, 또는 직접 GGUF 파일을 다운로드하려는 경우, Web UI에서 추가 옵션 ``gguf_model_path``를 지정하거나 명령줄에서 ``–gguf_model_path /path/to/model_quant.gguf``를 지정할 수 있습니다.
Lightning LORA 지원#
Lightning LORA는 LoRA 형태로 모델을 증류하여, 모델 성능을 유지하면서 추론 단계를 줄이고 추론 속도를 대폭 향상시킵니다. 현재 다음 모델이 이 LoRA를 지원합니다:
모델 |
지원되는 Lightning 버전 |
|
|---|---|---|
Qwen-Image |
4steps-V1.0-bf16, 4steps-V1.0, 8steps-V1.0, 8steps-V1.1-bf16, 8steps-V1.1 |
|
Qwen-Image-Edit |
4steps-V1.0-bf16, 4steps-V1.0, 8steps-V1.0-bf16, 8steps-V1.0 |
|
Qwen-Image-Edit-2509 |
4steps-V1.0-bf16, 4steps-V1.0-fp32, 8steps-V1.0-bf16, 8steps-V1.0-fp32 |
|
4단계 또는 8단계는 추론 단계 수( num_inference_steps )를 의미합니다. lightning_version 이 지정되면 Xinference가 자동으로 추론 단계 수를 설정합니다.
사용 시, 인터페이스에서 lightning 버전을 선택하거나 명령줄을 통해 지정할 수 있습니다.
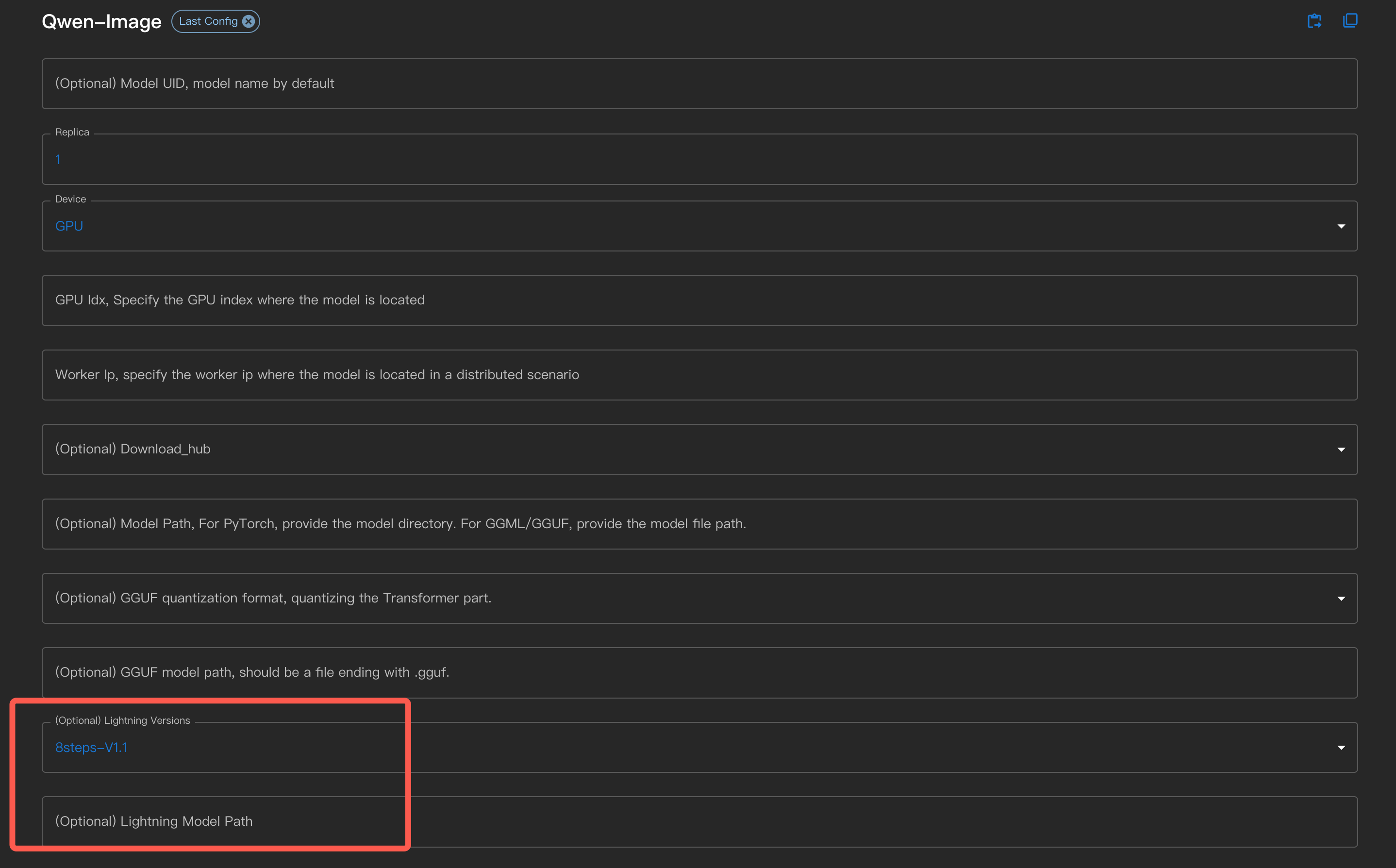
명령줄에서 ``–lightning_version <version>``을 사용하십시오.
Lightning LoRA 파일을 직접 다운로드한 사용자는 인터페이스에서 Lightning Model Path로 지정하거나 명령줄 인자 --lightning_model_path 를 사용할 수 있습니다.
예를 들어, ``4steps-V1.0``을 사용하면 추론 시간이 기존 34초에서 3초로 줄어듭니다.
OCR#
OCR API는 이미지 바이트를 받아 OCR 텍스트를 반환합니다.
cURL 또는 Xinference의 Python 클라이언트를 통해 OCR API를 시도할 수 있습니다.
curl -X 'POST' \
'http://<XINFERENCE_HOST>:<XINFERENCE_PORT>/v1/images/ocr' \
-F model=<MODEL_UID> \
-F 'kwargs={"model_size":"large"}' \
-F image=@xxx.jpg
from xinference.client import Client
client = Client("http://<XINFERENCE_HOST>:<XINFERENCE_PORT>")
model = client.get_model("<MODEL_UID>", model_size="large")
with open("xxx.jpg", "rb") as f:
model.ocr(f.read())
<OCR result string>